Customizing robotic behaviors to be aligned with diverse human preferences is an underexplored challenge in the field of embodied AI. In this paper, we present Promptable Behaviors, a novel framework that facilitates efficient personalization of robotic agents to diverse human preferences in complex environments. We use multi-objective reinforcement learning to train a single policy adaptable to a broad spectrum of preferences. We introduce three distinct methods to infer human preferences by leveraging different types of interactions: (1) human demonstrations, (2) preference feedback on trajectory comparisons, and (3) language instructions. We evaluate the proposed method in personalized object-goal navigation and flee navigation tasks in ProcTHOR and RoboTHOR, demonstrating the ability to prompt agent behaviors to satisfy human preferences in various scenarios.
Imagine a robot navigating in a house at midnight, asked to find an object without disturbing a child who just fell asleep.
The robot is required to explore the house thoroughly in order to find the target object, but not collide with any objects to avoid making unnecessary noise.
In contrast to this Quiet Operation scenario, in the Urgent scenario, a user is in a hurry and expects a robot to find the target object quickly rather than avoiding collisions.
These contrasting scenarios highlight the need for customizing robot policies to adapt to diverse and specific human preferences.
However, conventional approaches have shortcomings in dealing with diverse preferences, since the agent has to be re-trained for each unique human preference.
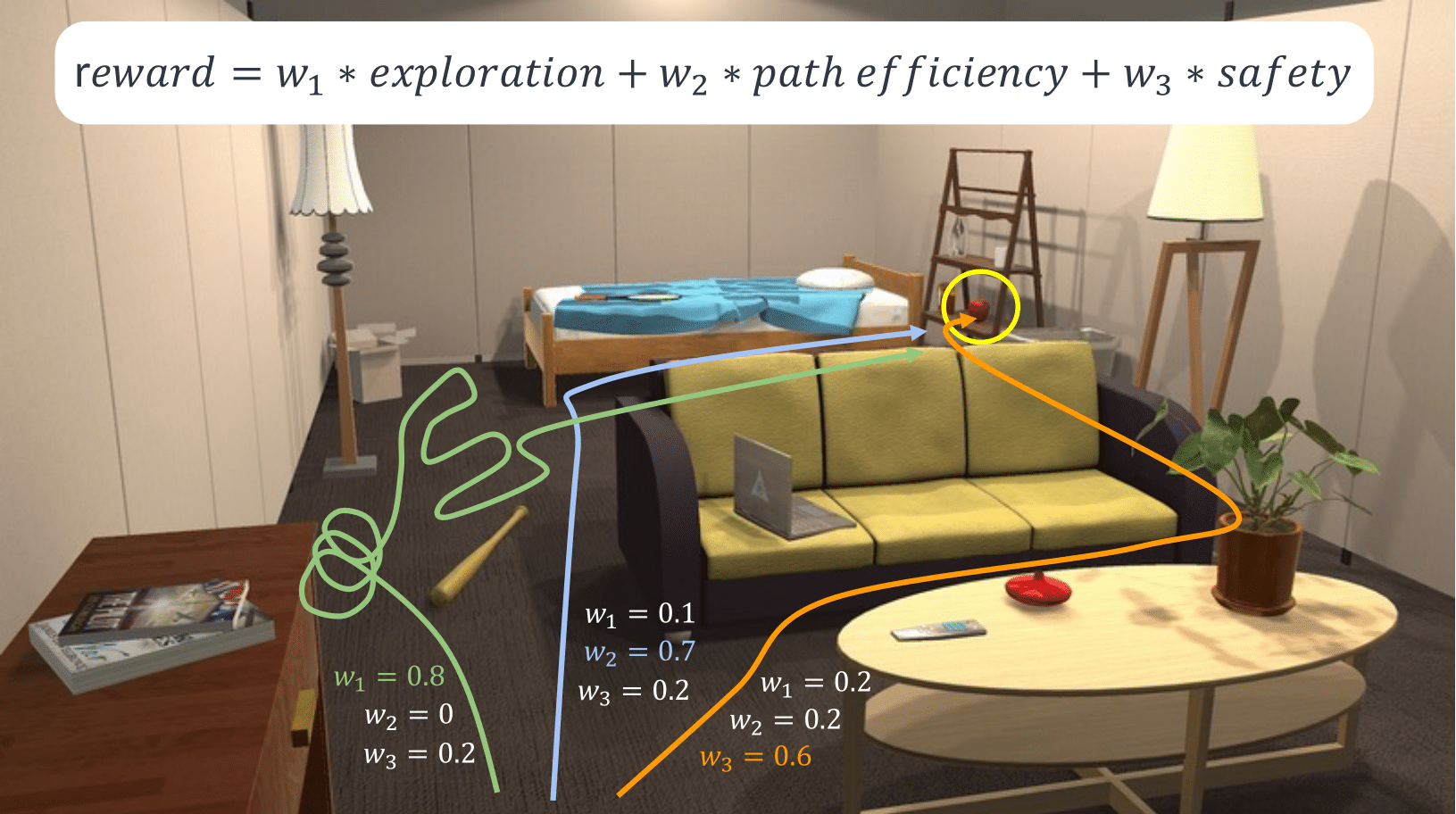
We propose Promptable Behaviors, a novel personalization framework that deals with diverse human preferences without re-training the agent. The key idea of our method is to use multi-objective reinforcement learning (MORL) as the backbone of personalizing a reward model. We take a modular approach:
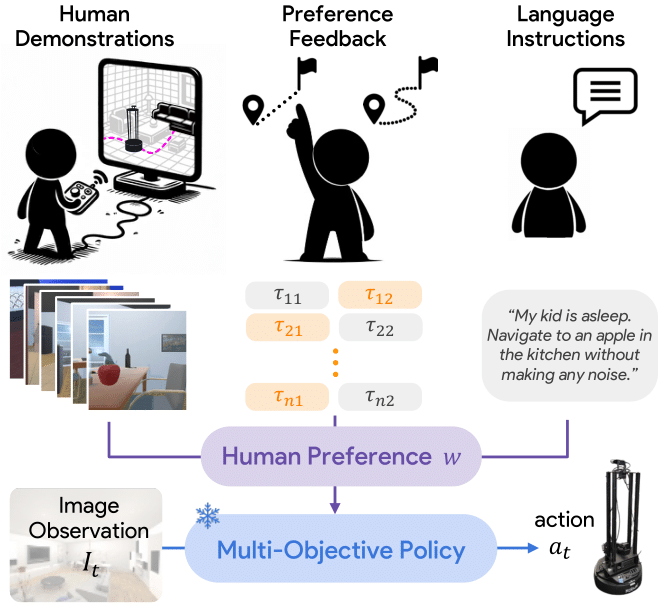
We evaluate our method on personalized object-goal navigation (ObjectNav) and flee navigation (FleeNav) in ProcTHOR and RoboTHOR, environments in the AI2-THOR simulator. The policy is evaluated across various scenarios to ensure that it aligns with human preferences and achieves satisfactory performance in both tasks. We show that the proposed method effectively prompts agent behaviors by adjusting the reward weight vector and infers reward weights from human preferences using three distinct reward weight prediction methods.
For instance in ObjectNav, when house exploration is prioritized, the proposed method shows the highest success rate (row j in Table 1), 11.3% higher than EmbCLIP, while Prioritized EmbCLIP shows the lowest success rate (row d in Table 1) among all methods and reward configurations. Additionally, our method achieves the highest SPL and the path efficiency reward when path efficiency is prioritized (row i in Table 1), outperforming EmbCLIP by 19.3% and 56.1%, respectively. This implies that the proposed method effectively maintains general performance while satisfying the underlying preferences in various prioritizations.
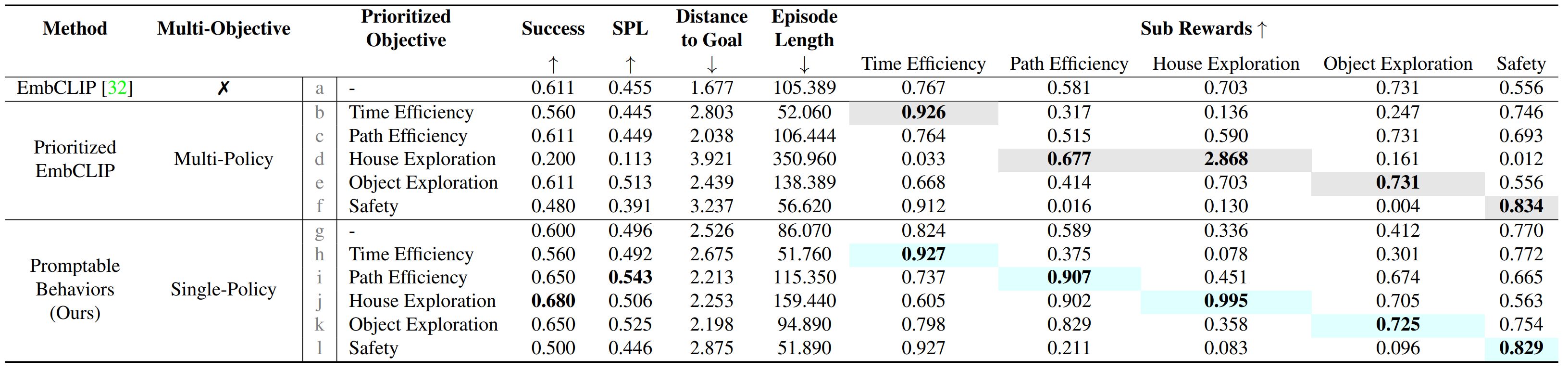
Table 1. Performance in ProcTHOR ObjectNav. We evaluate each method in the validation set with six different configurations of objective prioritization: uniform reward weight across all objectives and prioritizing a single objective 4 times as much as other objectives. Sub-rewards for each objective are accumulated during each episode, averaged across episodes, and then normalized using the mean and variance calculated across all methods. Colored cells indicate the highest values in each sub-reward column.

Figure 1. Trajectory Visualizations. In each figure, agent trajectory is visualized when an objective is prioritized 10 times as much as other objectives. The agent's final location is illustrated as a star.
We observe trade-offs between two conflicting objectives in ObjectNav: safety and house exploration. As we increase the weight for safety, the safety reward increases while the reward for its conflicting objective, house exploration, decreases.
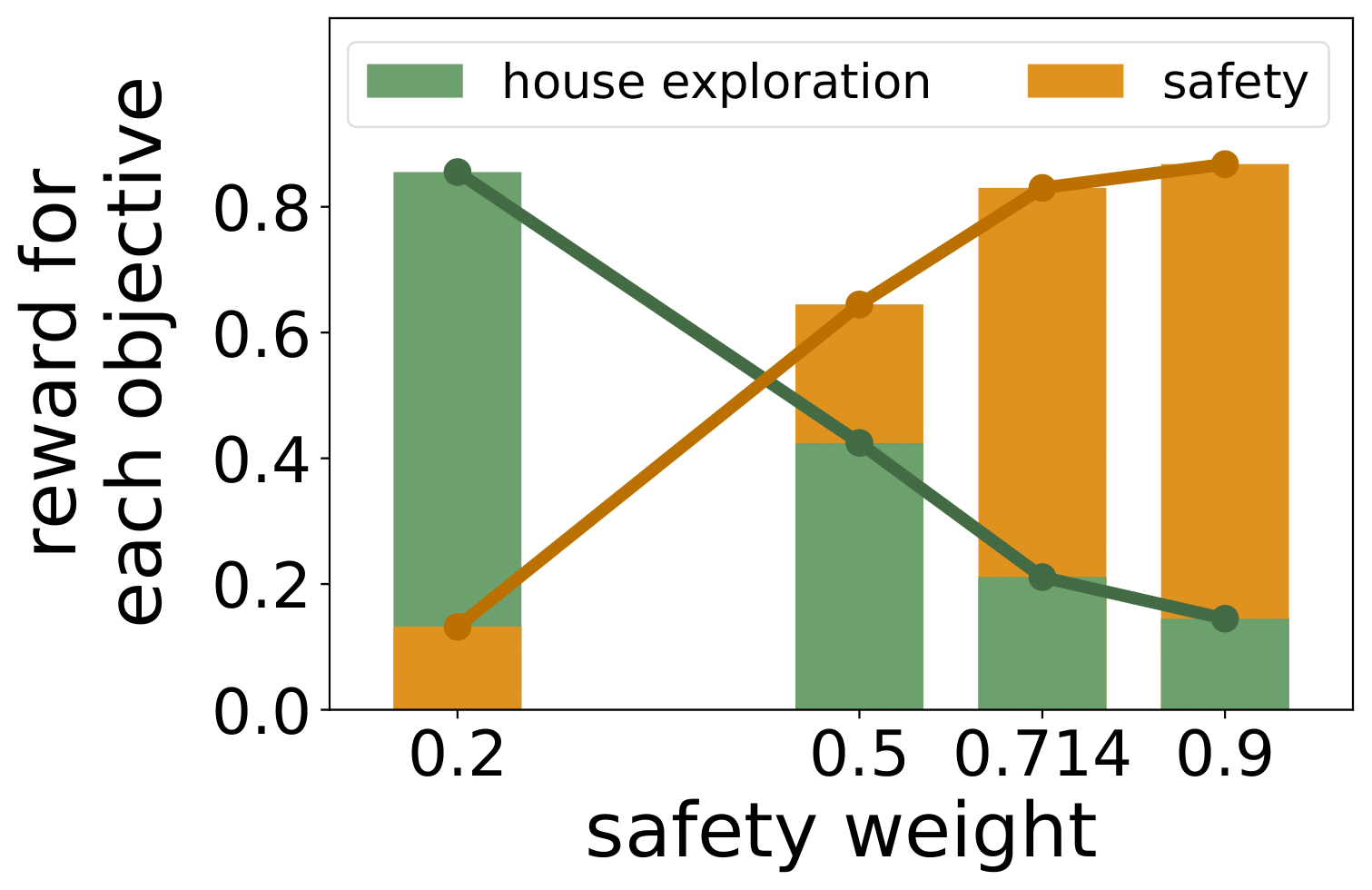
Figure 2. Conflicting Objectives. As we prioritize safety more, the average safety reward increases while the average reward of a conflicting objective, house exploration, decreases. We normalize the rewards for each objective using the mean and variance calculated across all weights.
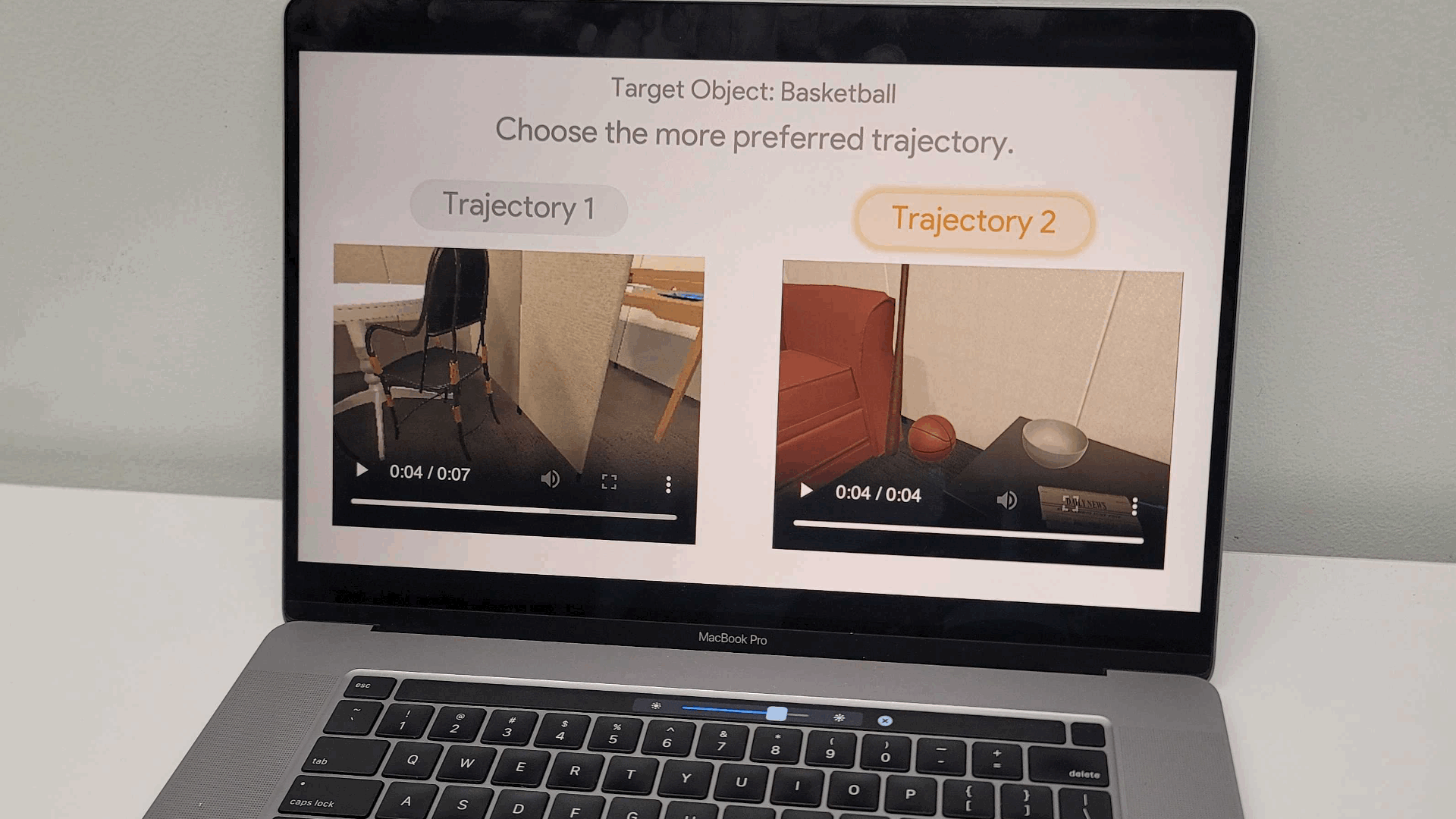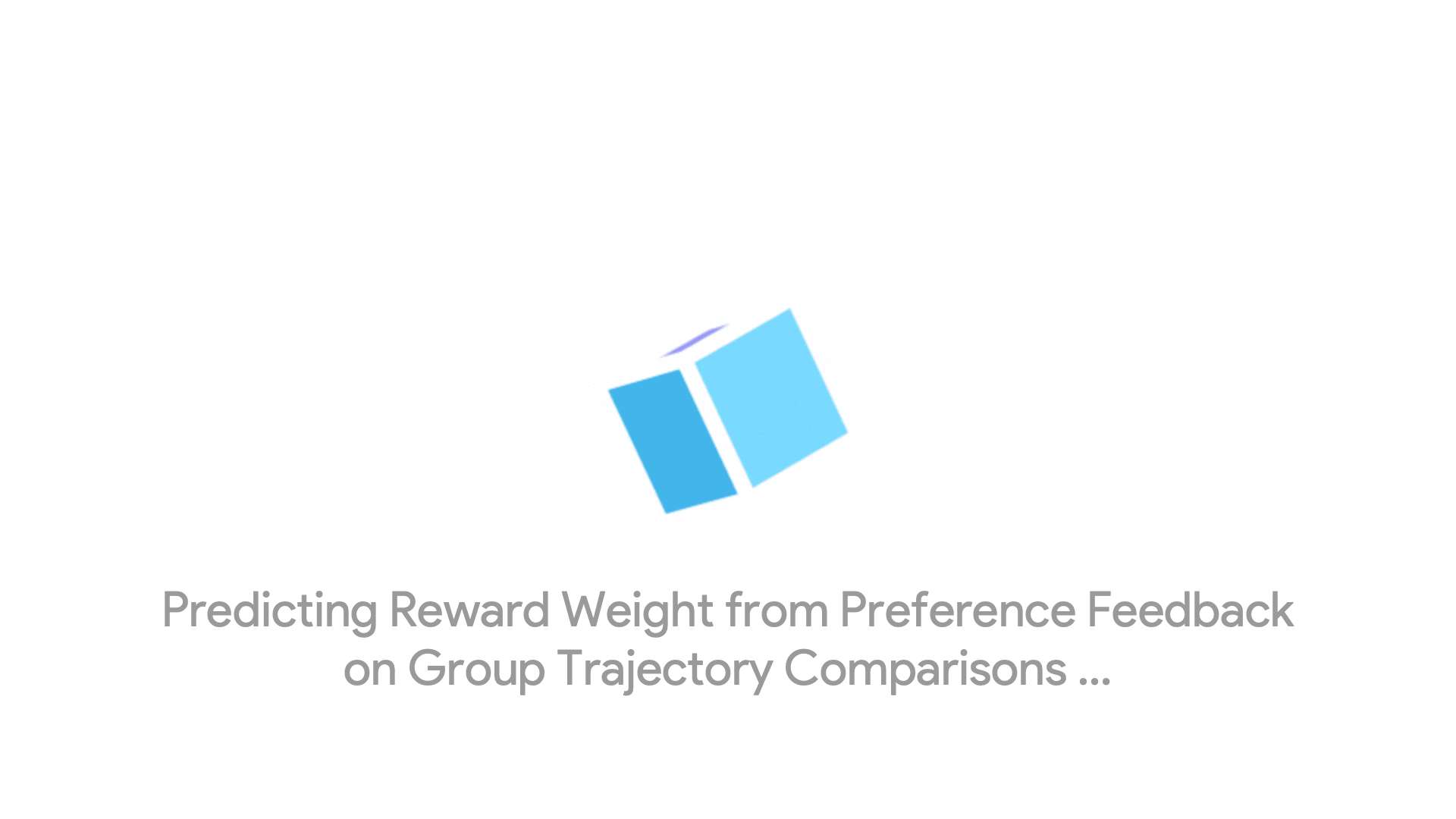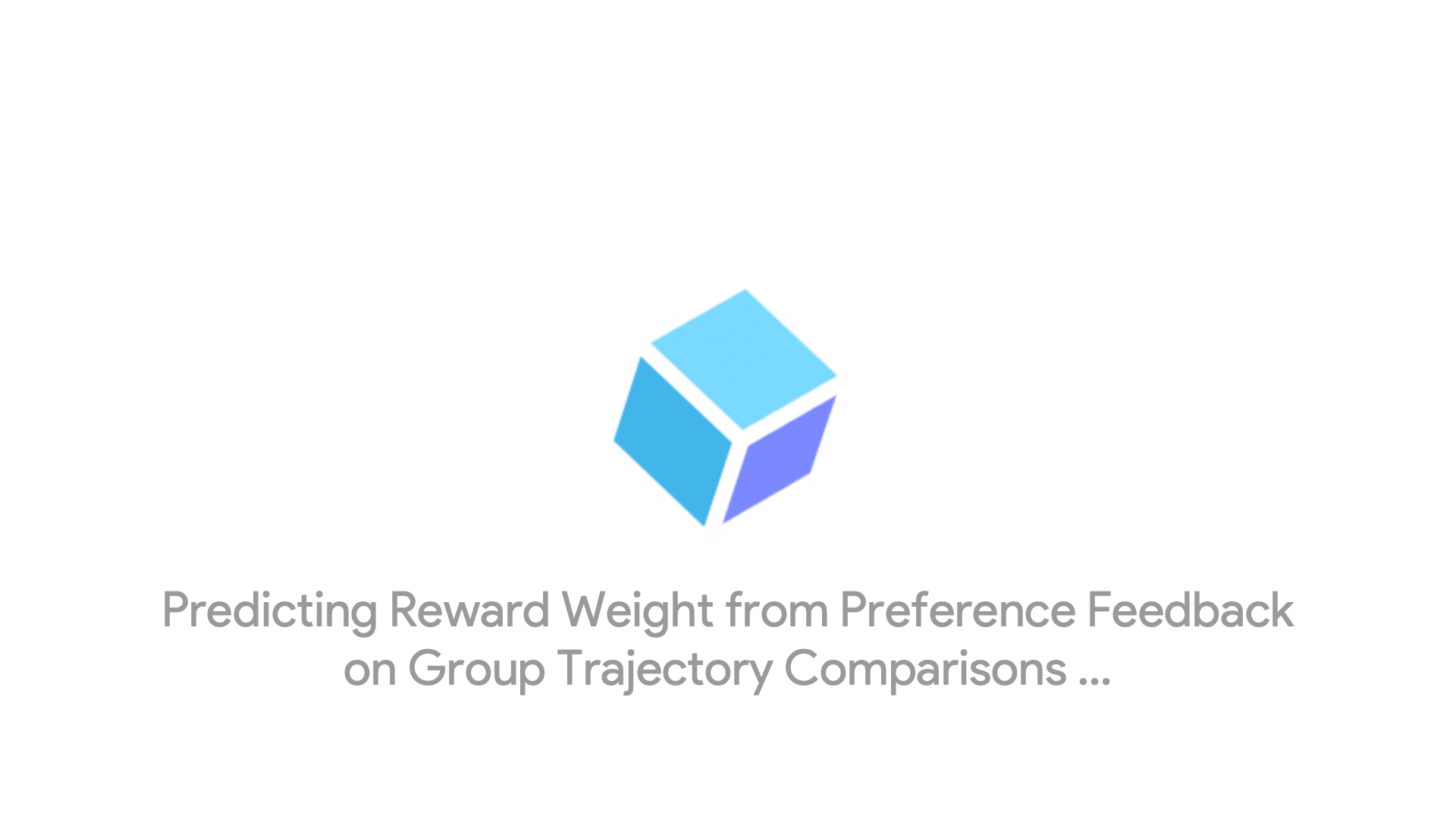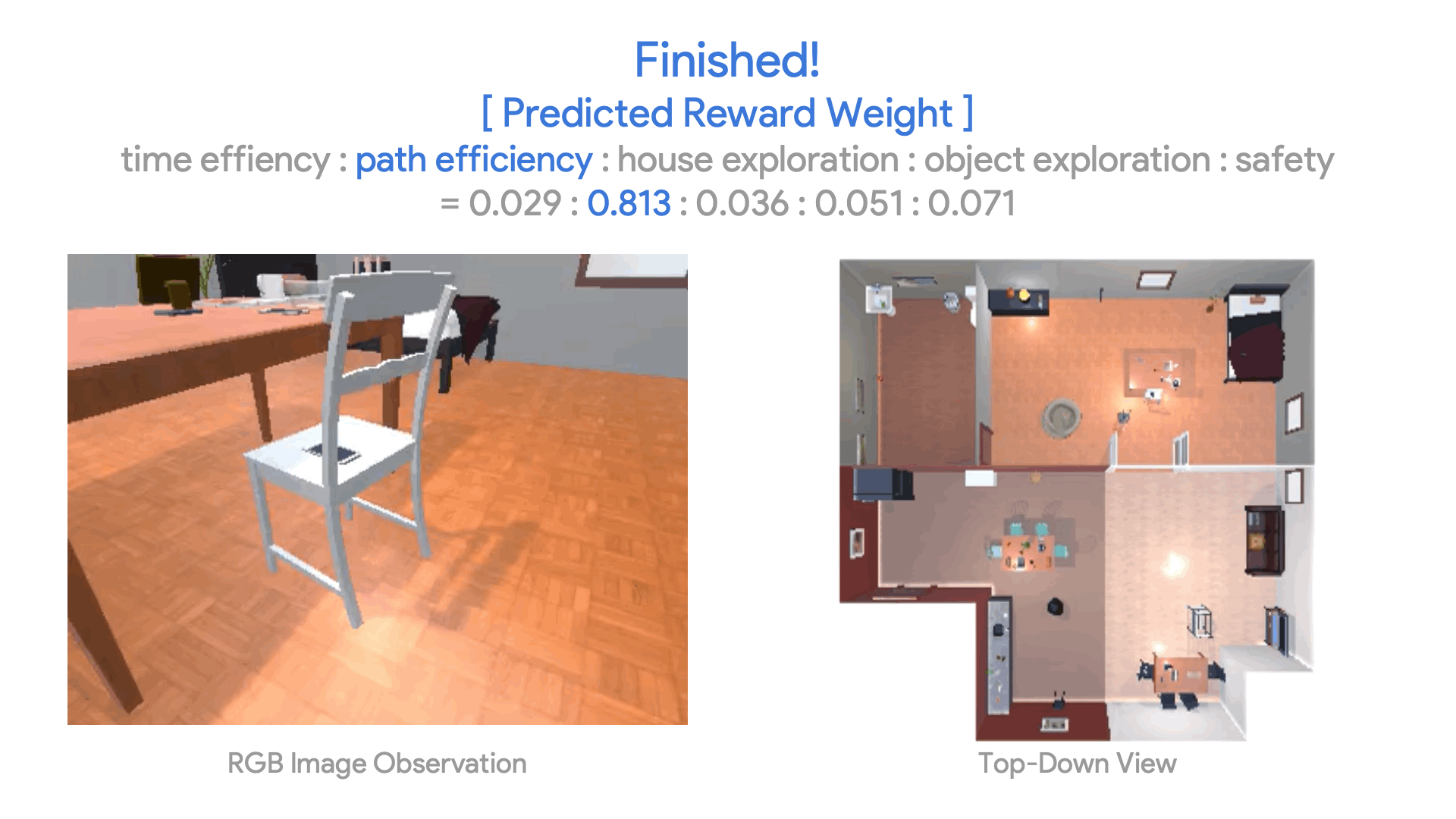
Now, we compare three reward weight prediction methods and show the results of Promptable Behaviors for the full pipeline. As mentioned above, the users have three distinct options to describe their preferences to the agent: (1) demonstrating a trajectory, (2) labeling their preferences on trajectory comparisons, and (3) providing language instructions. Table 2 shows the quantitative performance of the three weight prediction methods, each with its own advantage.
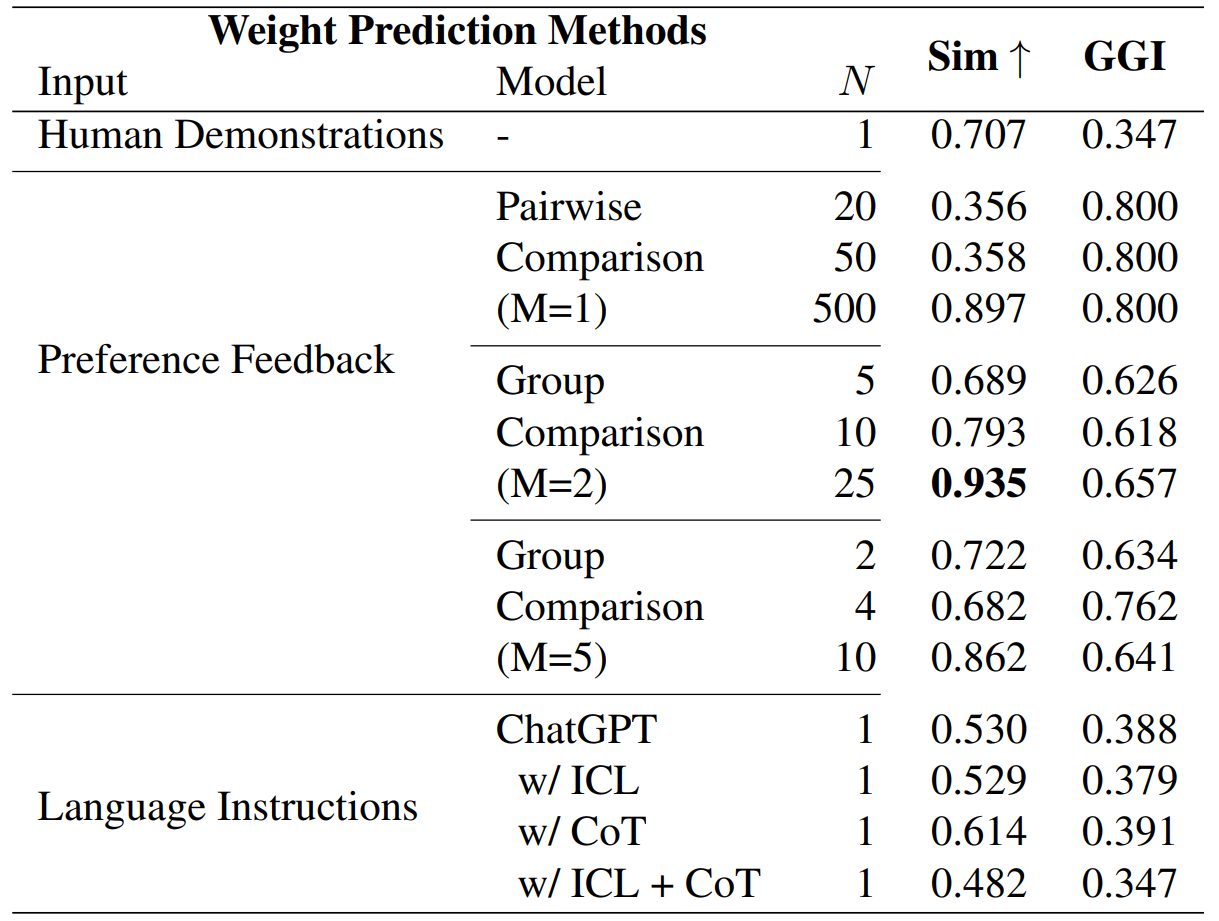
Table 2. Comparison of Three Weight Prediction Methods in ProcTHOR ObjectNav. We predict the optimal reward weights from human demonstrations, preference feedback on trajectory comparisons, and language instructions. We measure the cosine similarity (Sim) between the predicted weights and the weights designed by human experts. We also calculate generalized gini index (GGI) which measures the peakedness of the predicted weights
We also perform human evaluations by asking participants to compare trajectories generated with the predicted reward weights for different scenarios. Results in Table 3 show that group trajectory comparison, especially with two trajectories per group, achieves the highest win rate, significantly outperforming other methods by up to 17.8%. This high win rate indicates that the generated trajectories closely align with the intended scenarios.
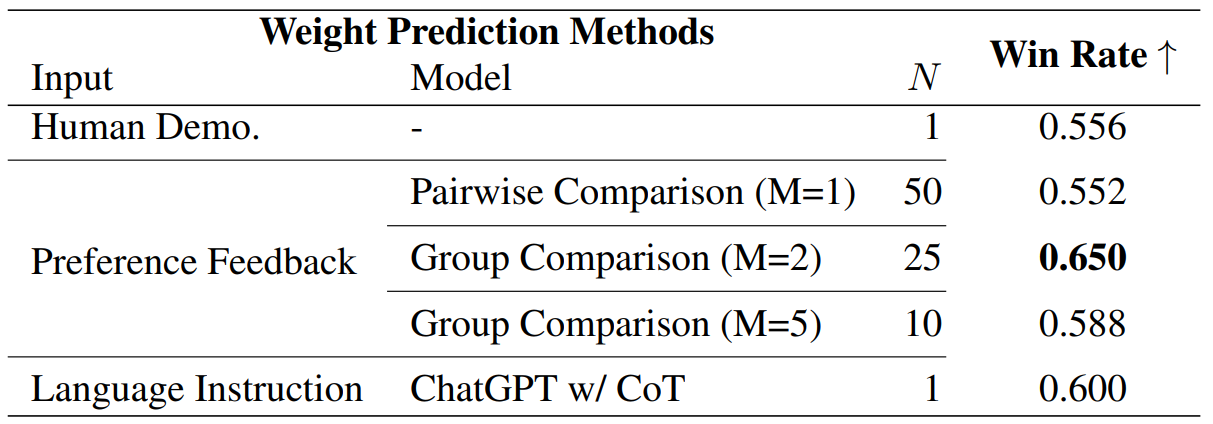
Table 3. Human Evaluation on Scenario-Trajectory Matching. Participants evaluate trajectories generated with the trained policy and the reward weights predicted for five scenarios in ObjectNav.
We conduct real human experiments given the five scenarios as follows: